
Part 2 — From Tribal Knowledge to Agent-Ready
Process Maps + Knowledge Stores

TL;DR To make your organization agent-ready, break documentation into small, well-labeled, and regularly updated pages that capture real workflows — including exceptions and the “why” behind decisions. Design docs for both humans and AI to retrieve easily. Use process maps, metadata, and the right indexing tools. When done right, agents and new hires can find answers quickly and reliably, reducing meetings and knowledge gaps.
Most teams I’ve seen live in a strange tension with documentation: we want to believe it’s in decent shape, but deep down we know it’s patchy. You can tell it’s a problem when an incident remediation starts with a sprint task to “figure out how this thing actually works.”
Behind that patchiness sits tribal knowledge: the undocumented decisions, brittle workarounds, and “ask Steve” steps that never make it to a page. It’s not because people are lazy. Good documentation is expensive. It takes time, context, and, most neglected of all, the why. Years later a new team wonders, “Why didn’t they just …?” The answer might be compliance, a technology or vendor limitation, or a disaster we already survived. If the why never got captured, we end up maintaining workarounds or re-learning old lessons the hard way.
Even when we do write things down, it snowballs. Pages expire. Owners change. We snooze the “review” ping, promise Future Us will tidy it up, all while living with knowledge concentration risk hoping our star player doesn’t get hit by the proverbial bus.
Nobody trusts the docs, so we schedule meetings. Wouldn’t it be great if your documentation was so strong that a new team member could read it and be proficient in the project? We all aspire to that but is it realistic?
Even with strong documentation, there’s still a tendency to schedule meetings. Either the documentation appears to be out of date, is incomplete, or we just don’t trust it. It’s also human nature to want to ask questions and maybe a bit of laziness to talk it through rather than studying the docs.
Humans are mediocre at keeping docs fresh but LLMs are great at drafting and refactoring. But even the smartest model is useless if there’s nothing reliable to retrieve. If you want agentic systems to work, you start with the boring work: documentation and process truth.
Writing for Readers and for Agents
If Part 1 was about picking the right class of work, Part 2 is about giving your agents something trustworthy to read. That means documenting differently than a giant Confluence wall.
RAG-First Writing — How to Make Docs LLM-Friendly

Write for RAG, not for browsing. A great doc is one a human can skim in 30 seconds and an agent can parse in 30 milliseconds. You don’t have to start from scratch but legacy documentation often requires additional work to optimize retrieval.
Workflow Truth Beats Handbook Fantasy
Most people can list the “steps” of a process. That’s not the process. The real process includes all the small workarounds that have been added over time, the loops, logic, and approvals nobody documents because they either don’t think about them or feel they are “obvious.”
I saw a viral video recently where a teacher reads her students’ papers on how to make a PB&J sandwich. She ends up with smashed bread, PB&J spread all over her arms and nothing that resembles a sandwich. If processes are not documented to include all the messy details, validations and exceptions, you’ll end up with a similar mess.
LLMs aim to be helpful and are trained to answer questions. Anything left to assumption will result in probabilistic “hallucination.”
If you want agents to help, you must thoroughly document the real workflow.
Start by clearly defining the beginning and end of the process at a high level and putting a box around areas of the process you intend to address.
Genchi Genbutsu (pronounced gen-chee gen-boot-soo) is a core principle of the Toyota Production System loosely translated as “go and see for yourself.” Operations managers know, you must sit with operators to really understand their process step by step.
Draw swim lanes for actors and systems; mark timers, controls, and error paths.
Keep an exceptions diary to document the weird cases that may require human in the loop (HITL) oversight.
If you have process-mining tools, run 90 days of event logs to see the real path.
“But We Already Have Docs” (Probably Not for Agents)
Even teams with A-grade documentation still hit two common agent-specific walls:
Documents are too big → models over-read and miss the clause that matters.
No metadata discipline → the index can’t rank the right chunk.
Fix it by design: split giant docs into linkable micro-pages, add consistent metadata, keep chunks 400–800 tokens, always log citations, and auto-deindex stale content.
Now when an agent gets “What counts as proof of address in the EU?”, it fetches the exact section, cites it, and acts accordingly.
A Quick Story — The Campaign-Approval Iceberg
Ask marketing how a campaign gets approved and you’ll hear five bullets.
Reality: a looping maze of tickets, Legal, Brand, Risk, Compliance, re-sign-offs, and Friday cut-offs.
Draw that. Label who approves, thresholds, artifacts, and logs. Suddenly an agentic assistant can help — prefill forms, chase missing items, assemble the approval trail, and flag the steps that still need humans.
RAG-First Checklist
Before you build the agent, make sure your knowledge base passes these quick checks:
Atomicity: no page > 1 topic.
Metadata: each page lists owner + system + project + review cadence + sensitivity. (adjust as needed)
Consistency: headings follow query-like patterns (“KYC → Accepted Docs → Region EU”).
Coverage: includes exceptions, not just happy paths.
Evaluation: run a 50–100 question test; verify answers cite correct sections.
If you can tick all five, your content is ready for RAG indexing — and your first agent will feel “intelligent” because you finally gave it clean truth to stand on.
Quick Comparison — Indexing Options for RAG
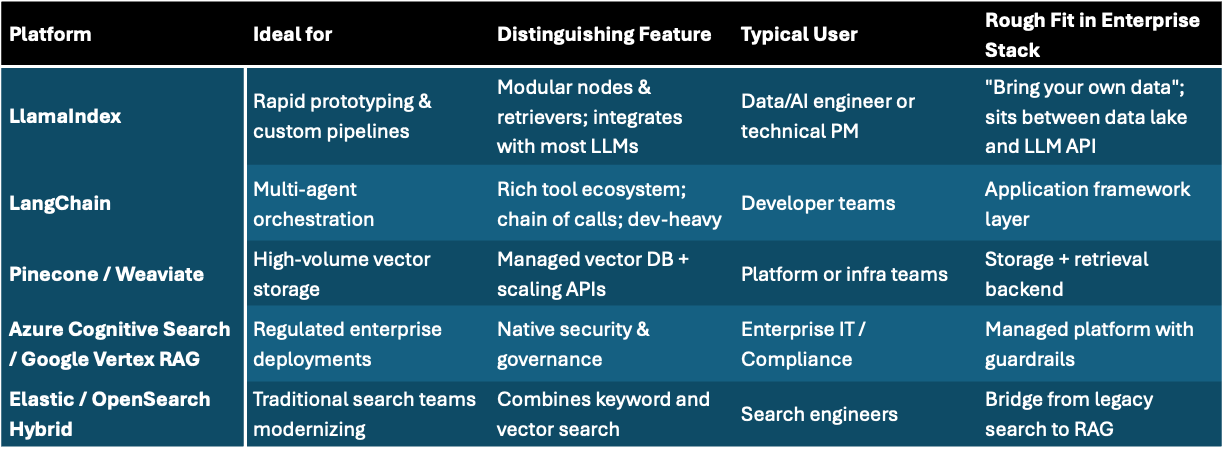
How to decide:
Start with LlamaIndex when you want to experiment fast and control structure.
Move to managed RAG platforms when governance, PII controls, and scale matter.
Pair with a vector store when your data volume outgrows notebooks.
Opinion: LlamaIndex is the “Excel” of RAG — simple enough to tinker, powerful enough to teach you how the math works before you industrialize it.
The First 30 Days

Your first win isn’t perfection; it’s predictable, auditable answers in a limited scope and controlled environment.
What “Good” Feels Like
New hires can self-serve 80% of cases.
Agents return answers with citations humans trust.
Documents maintained because pages have owners and cadence.
Teams understand why rules exist, not just that they do.
When you reach that point, your agents stop hallucinating, stop skipping steps, and start sounding like competent coworkers.
Next Up — Part 3
We’ll take these maps and curated knowledge and go production: identity for agents, least-privilege tool access, runtime guardrails, monitoring, and an ROI dashboard that survives audit season.
Brilliant analysis! What about the "why" in agent readiness?